人气排行榜
人气排行榜爬虫代理ip怎么加 (爬虫代理ip巨量http 代理ip多)
爬虫代理IP是用于在数据抓取过程中隐藏真实IP地址的工具,它能够帮助爬虫程序在访问网站时绕过反爬虫机制,保护被爬取网站和爬虫程序本身的安全。当需要应对大规模数据采集或对特定网站进行持续爬取时,使用代理IP是一种常见的方法。那么,如何加入爬虫代理IP呢?接下来将从不同角度分析这个问题。
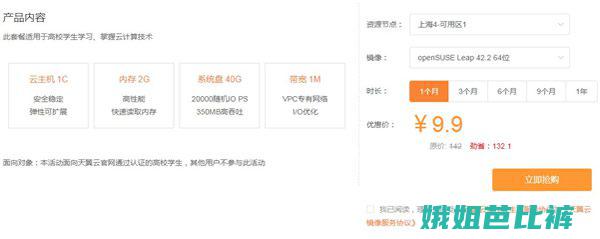
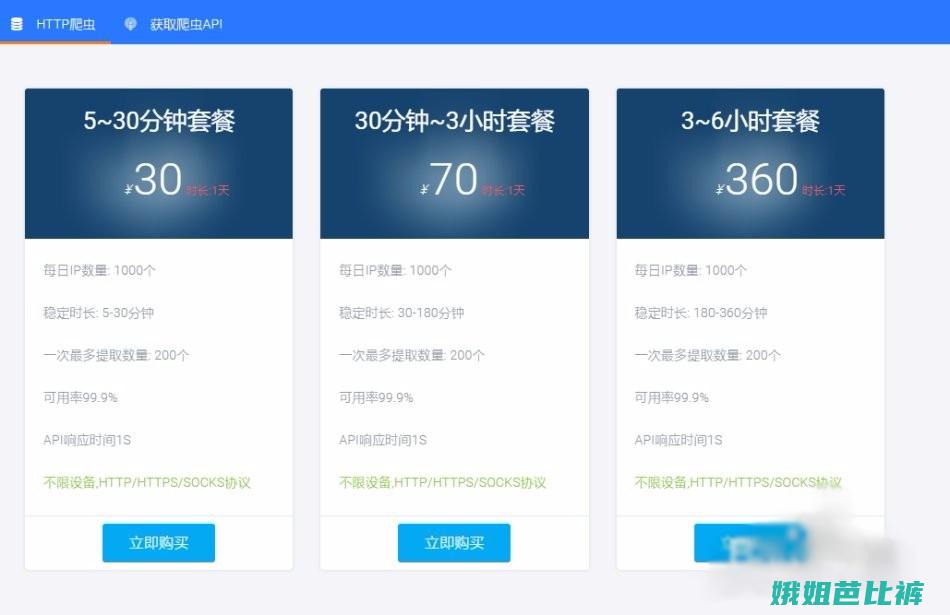
要获取大量的HTTP代理IP。爬取代理IP网站是一种常见的方法,通过访问提供代理IP的网站,可以得到大量的代理IP地址和端口信息。这些代理IP通常有不同的匿名级别和稳定性,选择合适的代理IP非常重要也可以使用付费IP代理服务商提供的IP池,确保获取高质量和稳定的代理IP资源。
在爬虫程序中加入代理IP的方法有多种。一种常见的法是利用Python的requests库或Scrapy框架,通过设置代理IP参数,实现在请求网站时使用代理IP访问。例如,在requests库中,可以通过设置proxies参数来指定代理IP地址和端口,从而现代理访问。在Scrapy框架中,可以通过middlewares中间件机制,编写自定义的代理IP中间件,实现对每个请求加入代理IP的逻辑。
除了以上方法,还虑使用代理池来管理代理IP资源。代理池是一种动态管理代理IP的机制,可以定时检测代理IP的可用性,并自动替换无效的代理IP。通过使用代理池,可以帮虫程序更加稳定和持续地运行,提高数据采集的效率和成功率。
需要注意的是,加入代理IP可能会增加网络请求的延迟和复杂度,因此在代理IP时需要考虑网络性能和程序稳定性。为了提高效率,可以尝试使用多线程或异步请求的方式,在多个代理IP之间进行轮询或并发请求,从而快速地抓取数据并高爬取速度。
加入爬虫代理IP是爬虫程序中重要的一环,可以有效地提升数据采集的成功率和安全性。通过获取大量的代理IP资源、合设置代理IP参数、使用代理池管理代理IP等方式,可以帮助爬虫程序更好地应对网站反爬虫机制和提高数据抓取效率。希望以上分析对您有所帮助。
相关标签: 爬虫代理ip巨量http、 代理ip多、 爬虫代理ip怎么加、
本文地址:http://www.29bbk.com/article/928.html
<a href="http://www.29bbk.com/" target="_blank">娥姐芭比裤</a>